Project #2 - B+Tree
项目准备
项目地址:Project #2 - B+Tree
准备工作:阅读 Chapter 14.5 24.5 14.1-14.4 18.10.2,学习 Lecture #07 #08 #09,以及阅读课堂笔记。
Task #1 - B+Tree Pages
实现
① 第一个比较迷惑的点就是 max_size_ 的含义,对官方提供的B+Tree进行插入操作,发现叶子节点的 size_ 不会到达 max_size_。难道叶子节点实际只能包含 max_size_ - 1 个 key 吗?通过查看项目地址中的 Requirements and Hints 可以发现,官方建议叶子节点在插入后大小达到 max_size_ 时,进行分裂,内部节点在插入前大小达到 max_size_ 时进行分裂。所以对于内部节点,max_size_ 表示它能包含的指针数量;对于叶子节点,max_size_ 表示它能包含的键值对数量。
② GetMinSize 的实现,同样参考官方示例,对于非叶子节点,返回 (max_size_ + 1) / 2;对于叶子节点,返回 max_size_ / 2。为什么要这样,参考第 ① 点也就明白了,这样可以保证分裂后的两个节点的大小都至少为最小大小,所以该方法的实现实际上取决于分裂的具体实现(即何时分裂)。
补充
① 如何理解 MappingType array_[0],注释表示它是 Flexible array member for page data,参见维基百科Flexible array member。似乎是 C 语言的特性,C++ 标准不支持,但是 C++ 的编译器普遍会支持。
② 在内部节点和叶子节点中,array_ 的唯一区别就是在搜索内部节点时不能使用 array[0]_.first,因为它并不能准确表示 array_[0].second 中 key 的范围(向 array_[0].second 中插入一个更小的 key,它就失效了)。
Task #2a - B+Tree Insertion and Search for Single Values
实现
① 比较纠结的是既然要使用二分查找,如何保证节点内部 key 的有序性,因为是使用数组存储的,所以似乎只能花费 \(O(n)\) 时间来移动元素了?或者可以加一个数据结构存下标,来保证有序性,但是涉及分裂和删除操作还是比较难搞的,暂时不优化。
② 可以在 BPlusTreeInternalPage 和 BPlusTreeLeafPage 中添加 Search 函数,来实现二分查找指定 key。内部节点一定可以找到一个满足条件的位置(因为我们找的实际上是指针),而叶子节点如果找不到指定 key,那么就返回 -index - 1(方便之后插入,类似 Java 中的 BinarySearch)。具体的实现逻辑:
- 内部节点从位置 1 开始找第一个大于 key 的键,返回它左边位置,即
index - 1。 - 叶子节点从位置 0 开始找第一个大于等于 key 的键,如果越界或者键值不等于 key,则返回
-index - 1,否则返回index。
③ 特别注意 PageGuard 的使用,只有当操作完页面之后,才对其进行 Drop 操作(移动赋值以及匿名对象的析构都会导致该操作)。并且用完页面后及时 Drop,这样可以尽早释放页面的锁以及 Unpin 页面。插入时,利用 latch crabbing 技巧,先拿到下个页面的锁,然后根据页面大小判断是否 Drop 上个页面(使用 Context)。注意拿锁和 Drop 的顺序,以及该大小判断依赖于分裂的实现,详细见 Task #1 - B+Tree Pages ①。
④ 获取页面需要进行类型转换,如果只读不写就使用 page_guard.h 中提供的 As 函数,只有需要写页面时才使用 AsMut 函数,因为该函数会将页面置为脏页。先将其转换为 BPlusTreePage,然后再根据页面类型,将其转换为内部节点或叶子节点,注意 BPlusTree 类中已经为我们提供了别名:
1 | using InternalPage = BPlusTreeInternalPage<KeyType, page_id_t, KeyComparator>; |
一开始我没有注意,在对内部节点转换时,误将其 page_id_t 转为 ValueType,导致完全误解了整个项目的结构。
⑤ 分裂叶子节点和内部节点时,注意判断当前节点是否是根节点。我们可以在 BPlusTreeInternalPage 和 BPlusTreeLeafPage 中添加 Split 函数,来实现分裂。
叶子节点的分裂操作比较简单,就是移动然后设置大小,为了不让页面类和其他类耦合(BufferPoolManager,Context),我将分裂函数的参数设计为 BPlusTreeInternalPage &new_page,它会返回将插入到上层的 key,即新节点的第一个 key。
内部节点的分裂操作比较复杂,并发测试时遇到边界样例才发现,因为内部节点的分裂是插入前分裂,所以还需要考虑插入的那个键的大小。如果 key 比 array_[GetMinSize() - 1] 小,则插入到当前节点,否则插入到新分裂的节点。并且,在插入新分裂的节点时,可能会插入到索引为 0 的位置,这一点要特别注意。最后,也是返回新节点的第一个 key(指的是 array_[0].first,因为分裂的时候复制了)。
⑥ 同理,在内部页面和叶子页面类中可以添加 Insert 函数。需要注意的是,这两个函数的实现有些点不同。对于内部节点,当 B+Tree 的根节点分裂时,该情况会将 page_id 插入到内部节点的第一个没有键的位置,所以我们可以将参数设计为 const std::optional<KeyType> &opt 来区分这种情况。对于叶子节点,由于不能有相同的键,所以根据 Search 的实现,当 index ≥ 0 时返回 false,否则继续插入。
调试
调试时可以先使用可视化网站查看 B+ 树,方便定位问题,我们可以使用 shell 脚本一键生成文件(解决方案):
1 | !/bin/bash |
在生成文件时可能会报 [b_plus_tree.cpp:356:Draw] WARN - Drawing an empty tree 错误,原因是我们没有实现 b_plus_tree.cpp 中的 IsEmpty 函数。
补充
① 如何使用 upper_bound 和 lower_bound(Java 选手表示踩了很多坑),可以看看 cppreference 的示例代码,尤其注意 lambda 表达式的使用(参数顺序,以及大小的比较)。
② 测试时忽略 iterators 的测试。
③ GetValue 注意特判根节点是否存在,否则可能引发空指针异常(依赖于 BufferPoolManager 的实现)。
Task #2b - B+Tree Deletions
实现
① 删除操作可以分为两种情况,相邻节点重新分配和相邻节点合并。进一步可以划分为操作当前节点的左节点,还是右节点。需要注意的是,我们只有对相同父节点的两个子节点执行上述操作,一个非根节点必定有一个同父的左节点或右节点。(如果不这样限制,实现起来会很麻烦,需要找到最近公共祖先,做键值的替换。)为了能够获取左右节点的页面,我们在从上到下找 key 对应的页面时,可以同时保存左右页面的 page_id。
② 重新分配操作,需要区分左右。如果从右节点取,则需要更新右节点对应父节点中的 key;如果从左节点取,则需要更新当前节点对应父节点中的 key。操作完可以直接返回。
③ 合并操作同理,只不过不是更新,而是删除对应父节点中的 key(递归删除)。注意,如果合并叶子节点,需要同时更新 next_page_id_。(合并之后右侧的页面永远都不会被使用,或许需要对其执行 DeletePage 操作,在 DeletePage 之前需要 Drop/Unpin 页面。有个疑问,DeletePage 之前 Drop 之后,如果有线程 Fetch,那么删除页面的操作就会失败。)
调试
实现的思路弄明白后,大方向上就不会出错,但是很多细节容易写错:变量名字,重复执行 pop_back() 操作,删除页面后对页面进行操作等等。不过,说实话官方提供的可视化类真好用,Debug 全靠可视化来定位问题。磨磨蹭蹭,花费一天时间,做得有点慢。
Task #3 - An Iterator for Leaf Scans
基本上没有难度,遇到唯一的错误就是把 GetSize 打成了 GetMaxSize(因为用的自动补全)。
Task #4 - Concurrent Index
① 遇到问题,先定位它是什么问题。首先,应该解决非并发问题,我们可以在插入和删除的开头加一把大锁,然后利用并发测试 MixTest2,来混合查找、插入和删除操作,看看是否存在问题。为了尽可能引发问题,可以将叶子节点和内部节点的最大大小修改为 2 3,将 total_keys 修改为 1000,尽可能的触发分裂和合并操作(这个测试,比线上测试还强,多跑几次线上能过的给报错了)。在混合时,可以分别混合查找和插入,查找和删除,插入和删除,这样方便定位问题出在哪里。然后,再去进行并发优化,一点一点优化,边优化边测试,这样就不会因为找不到 Bug 的位置而发愁啦。
② 遇到错误,[disk_manager_memory.h:104:ReadPage] WARN - page not exist,发现是 BufferPoolManager 的 Bug,需要跑回去修复。一天后,终于真正的把 Bug 修好了,代码也稍微重构了一下,哈哈,真的 99% 不会报错(有个 FetchPageBasic/Read/Write 返回 nullptr 的错误没修复,报错概率很低,以后有问题再修),不得不说本地测试用例修改后是真的强劲,线上强度不够啊。(但是重构了个寂寞,效率没变,难受啊)
③ B+Tree 的并发问题其实基本没有,都是单线程问题或者 BPM 的并发问题,B+Tree 的并发只要注意 Fetch 和 Drop 的顺序就 OK。
(Optional) Leaderboard Task
① 初次提交通过,排名还挺高。额,多次提交能差七八万。感觉测试有问题,平均 QPS 也就十万多。
② 优化暂时搁置。
| Rank | Submission Name | read_qps | write_qps | total_qps |
|---|---|---|---|---|
| 36 | ALEX | 200376 | 603 | 200980 |
测试结果
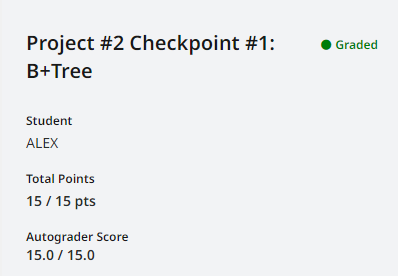
Checkpoint #1 说简单也不简单,感觉有些细节总是写错,包括下标的处理,C++ 二分查找函数的使用,变量名称,以及一些边界条件。说难也不难,线上测试首次提交就通过了。总共花了一天半吧。
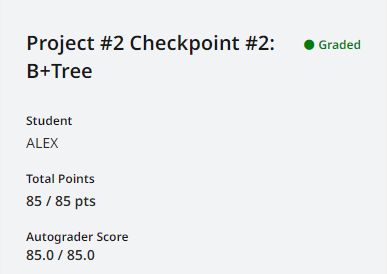
Checkpoint #2 总共花了两天,任务三四没什么难度,主要时间还是在删除操作,以及修复插入操作中的 Bug。
1 | !/bin/bash |
项目小结
开始做项目之前,对插入和删除具体怎么操作还是比较迷糊的,实际实现起来发现原来是这样的。特别需要注意别打错变量名,我用自动补全总是搞混 MaxSize 和 MinSize,还有各种变量都敲错,运行起来找 Bug 就头疼了。还要注意,内部节点和叶子节点分裂的时机不同,实现也不同,以及在分裂时如何对待内部节点的第一个 key。然后删除操作就是个分类讨论,弄明白就不难了。并发错误我也真是见识到了,BPM 优化需谨慎啊。(做得还是很慢,对大佬来说,其实就是个复杂点的模拟题吧)
Project #2 - B+Tree